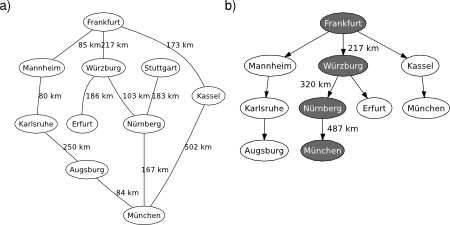
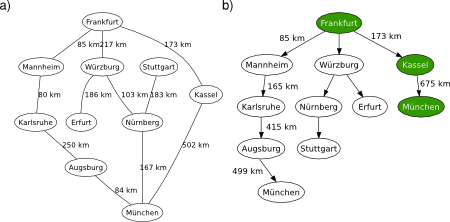
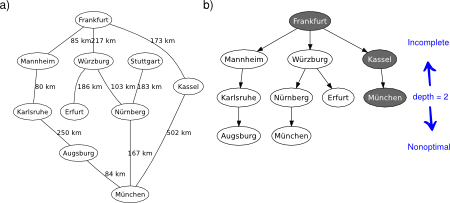
The depth-limited search (DLS) method is almost equal to depth-first search (DFS), but DLS solves the infinite state space problem because it bounds the depth of the search tree with a predetermined limit . Nodes at this depth limit are treated as if they had no successors. Thus, its time complexity is and its space complexity is ( is the branching factor). Note that DPS can be viewed as a special case of DLS with an infinite limit (in a sense, DLS is a more general approach). Also note that DLS is still incomplete (the given limit may be less than the depth of the solution) and nonoptimal (it may be greater), see Figure 1. However, in order to have an informed upper bound of the optimal depth limit, you can reasonably use the diameter of the state space (i.e., the longest shortest path between any two nodes defined by the problem).
Figure 1. DLS applied on the graphical map of Germany. Depth of solution from Frankfurt to München is 2. Source: Wikipedia. a) Problem description. b) Search tree.
The tree search version of DLS can be conveniently implemented by exploiting recursivity, see Figure 2. The frontier is not explicitly declared but inherently maintained in the stack of calls.
Figure 2a. Depth-limited tree search algorithm.
## @deftypefn {Function File} {@var{solution} =} depth_limited_search (@var{problem}, @var{start}, @var{finish}, @var{limit})
## Recursive implementation of depth-limited tree search.
##
## PRE:
## @var{problem} must be the cost-weighted adjacency matrix.
## @var{start} must be the starting node index.
## @var{finish} must be the finishing node index.
## @var{limit} must be the depth limit.
##
## POST:
## @var{solution} is the solution path. Zero if standard failure
## (no solution). One if cutoff failure (no solution within the
## depth limit).
## @end deftypefn
## Author: Alexandre Trilla <alex@atrilla.net>
function [solution] = depth_limited_search(problem, start, ...
finish, limit)
node.state = start;
node.parent = [];
node.cost = 0;
solution = recursive_dls(node, problem, finish, limit);
endfunction
Figure 2b. Recursive implementation of depth-limited tree search.
## @deftypefn {Function File} {@var{solution} =} recursive_dls(@var{node}, @var{problem}, @var{finish}, @var{limit})
## Recursive implementation of depth-limited tree search.
##
## PRE:
## @var{node} must be the starting node.
## @var{problem} must be the cost-weighted adjacency matrix.
## @var{finish} must be the finishing node index.
## @var{limit} must be the depth limit.
##
## POST:
## @var{solution} is the solution path. State set to zero if standard
## failure (no solution). One if cutoff failure (no solution within
## the depth limit).
## @end deftypefn
## Author: Alexandre Trilla <alex@atrilla.net>
function [solution] = recursive_dls(node, problem, finish, limit)
if (node.state == finish)
solution = node;
elseif (limit == 0)
solution.state = 1;
else
cutoff = 0;
for i = 1:size(problem, 2)
if (problem(node.state, i)>0)
if (i ~= node.state)
% expand search space
child.state = i;
path = node.parent;
path = [path node.state];
child.parent = path;
child.cost = node.cost + problem(node.state, i);
result = recursive_dls(child, problem, finish, ...
limit - 1);
if (result.state == 1)
cutoff = 1;
elseif (result.state ~= 0)
solution = result;
return;
endif
endif
endif
endfor
if (cutoff)
solution.state = 1;
else
solution.state = 0;
endif
endif
endfunction
Notice that DLS can terminate with two kinds of failure: the “no solution” standard failure, and the “cutoff” failure that indicates no solution within the given depth limit. In the next post, you are going to see how the accurate tracking of the given depth limit enables a DLS-inspired algorithm to be both complete and optimal. Stay tuned!